Are you juggling with large dataset and query performance management? Partitioning technique can unlock a new dimension for you. Let's explore the concepts deeply.
Divide and Conquer
Let's say you have millions of data in your Sales' table. It has proper indexing and it is also well maintained. Still you will observe performance issue. In this scenario, you can think of dividing the data vertically. For example, you can segregate data year wise. For example, 2022's data in one portion, 2023's data in another portion and so on. So, whenever, you need to search a data, you will jump into the appropriate partition and fetch it directly. Instead of finding from millions of data, now you are searching from a small portion which will enhance the performance.
Key Elements
Let's check some key elements crucial to partitioning.
Partitioning Function
A partition function is a database object that defines how rows in a table or index are distributed across partitions. It is a key component which maps the rows of a table or index to a set of partitions based on the value of a certain column. It specifies a range of values or list of values that determine the boundaries for each partition.
- LEFT Range: Boundary values belong to the left partition. It is the highest boundary value that will be included within a partition.
- RIGHT Range: Boundary values belong to the right partition. It is the lowest boundary value which will be included in each partition.
CREATE PARTITION FUNCTION PF_SalesDate (DATETIME)
AS RANGE LEFT
FOR VALUES ('2022-12-31', '2023-12-31', '2024-12-31');
Rows with dates:
- ≤ '2022-12-31' go to Partition 1.
- Between '2023-01-01' and '2023-12-31' go to Partition 2.
- And so on.
How It Works:
- Input: When a row is inserted into a table that uses a partition function, SQL Server evaluates the value in the partitioning column against the function's defined ranges or values.
- Output: The row is placed in the appropriate partition.
Partitioning Column
The partitioning column in SQL Server is the column used to determine how data is distributed across partitions in a partitioned table or index. This column's values are evaluated against the partition function, which defines the boundaries or conditions for each partition. Consider below criteria before selecting a partitioning column:
- If a Computed column used in a partition function, create it as PERSISTED.
- Only one column can be partition column. You can concatenate multiple columns with a computed column can be useful.
- Columns of all data types which can be used as index key is also candidate as a partitioning column, except timestamp.
- Columns of data types like ntext, text, image, xml, varchar(max), nvarchar(max), and varbinary(max), can't be partitioning column.
Partitioning Scheme
A partition function works in tandem with a partition scheme, which maps partitions to specific filegroups. This setup allows for distributing data across different physical storage locations.
Filegroups
You can place different partition to different file groups. For example, keeping older partitions to slower and less expensive storage will save your costs. However, it will make administrative tasks complex over the period. Better you keep all partitions in a single file groups unless you get benefit from backup and restore process.
Aligned Index
When an index is partitioned in the same way as its underlying partitioned table, its called Aligned Index. This alignment ensures that each partition of the index corresponds directly to a partition of the table. Aligned indexes are essential for maintaining efficient query performance and for supporting certain partitioning operations, like partition switching. For the aligned index, both the table and the index must use the same partition scheme and the partitioning column of the index must match the partitioning column of the table. The partition function of the index and the base table must be essentially the same, in that:
- The arguments of the partition functions have the same data type.
- They define the same number of partitions.
- They define the same boundary values for partitions.
Non-aligned Index
Non-aligned is an index that is partitioned differently from its corresponding table. In this case, the index uses a separate partition scheme, which may place it on a different file group or set of file groups from the base table. Creating a non-aligned partitioned index can be beneficial in scenarios such as:
- The base table is not partitioned.
- The index key is unique but does not include the table's partitioning column.
- You need the base table to participate in collocated joins with other tables that use different join columns.
Partitioning Clustered Indexes
At the time of partitioning a clustered index, the clustering key must contain the partitioning column. If the clustered index is unique, you must explicitly specify that the clustered index key contain the partitioning column.
Partitioning Nonclustered Indexes
When partitioning a unique nonclustered index, the index key must contain the partitioning column. When partitioning a nonunique, nonclustered index, the database engine adds the partitioning column by default as a nonkey (included) column of the index to make sure the index is aligned with the base table.
Partition Elimination
Partition Elimination is a process to access the relevant partitions of a partitioned table or index. This drastically reduces the amount of data scanned, improving query efficiency. When a query includes a filter on the partitioning column, SQL Server determines which partitions contain the required data and accesses only those partitions.
- it's scope is limited to the created database.
- if there is any NULL value in partitioned table, it falls into left partition.
- if NULL is used as first boundary value and RANGE RIGHT is used as partition function, then NULLs go to the second partition and first partition becomes empty.
Implementation
Let's create a table, partition function and partition scheme.
-- Partition Table
CREATE TABLE [dbo].[PartTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[created] [datetime] NULL,
CONSTRAINT [PK_PartTable] PRIMARY KEY ONCLUSTERED
[id] ASC) ON [PRIMARY])
ON [PS_PartDate]([created])
-- Partition Function
CREATE PARTITION FUNCTION PF_PartDate (DATETIME)
AS RANGE LEFT FOR VALUES ('2020-12-31', '2021-12-31', '2022-12-31', '2023-12-31', '2024-12-31');
-- Partition Scheme
CREATE PARTITION SCHEME PS_PartDate
AS PARTITION PF_PartDate
ALL TO ('PRIMARY') ;
Now, from SSMS follow below steps to create partition on the PartTable.
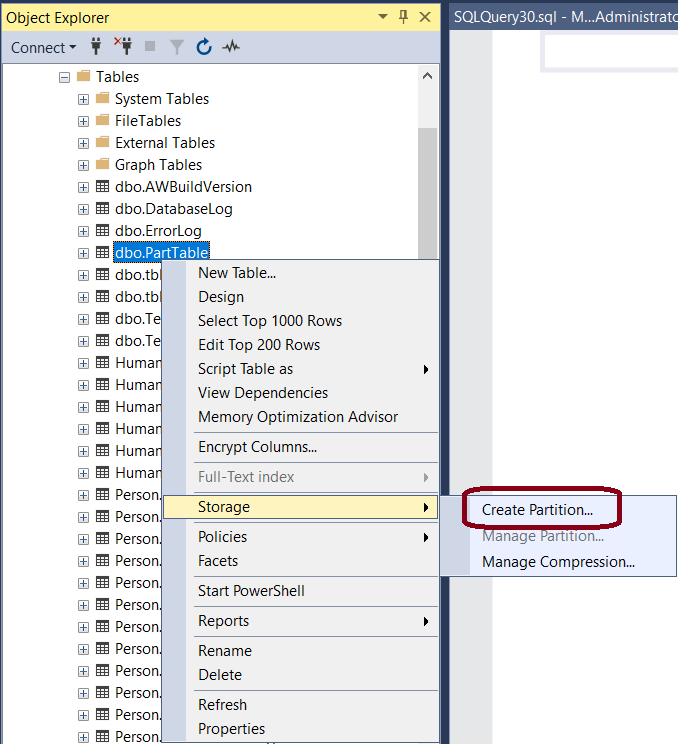
Picture-1:- Choosing Create Partition Option
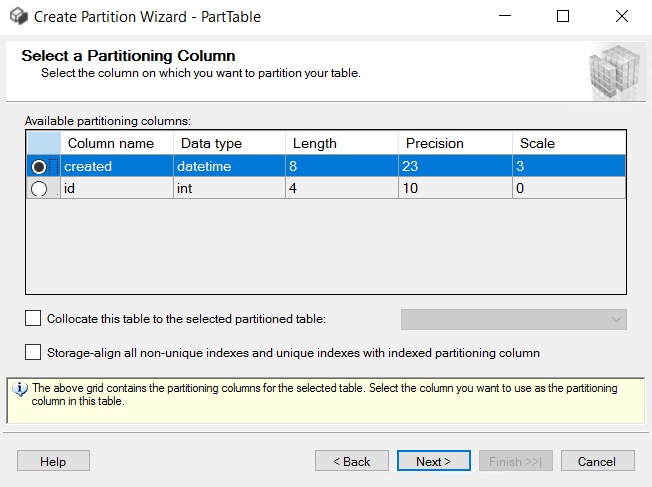
Picture-2:- Selecting partition column
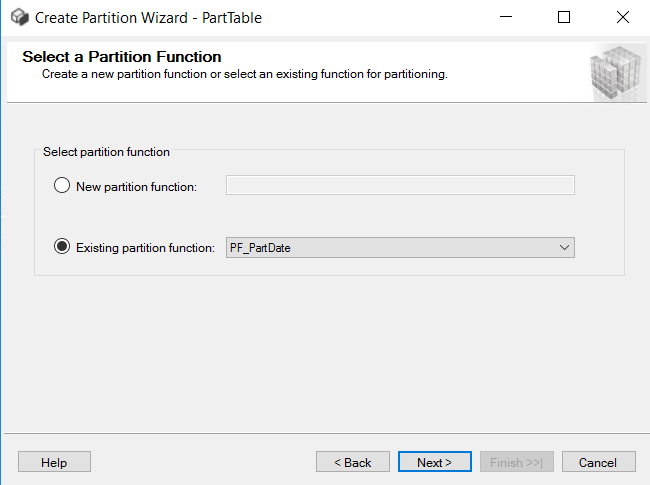
Picture-3:- Picking the partition function
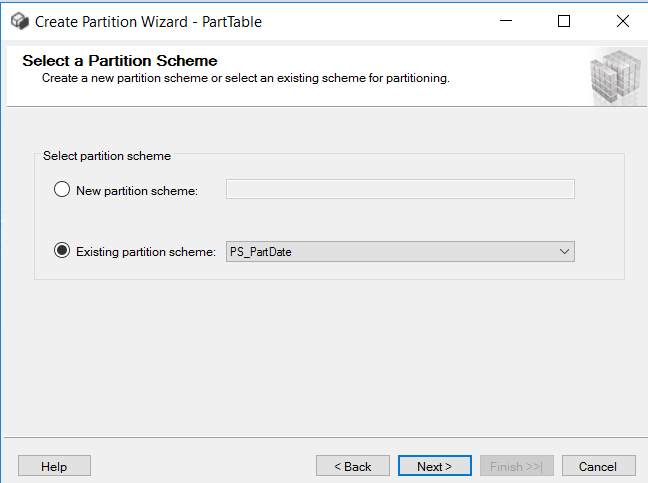
Picture-4:- Selecting the partition scheme
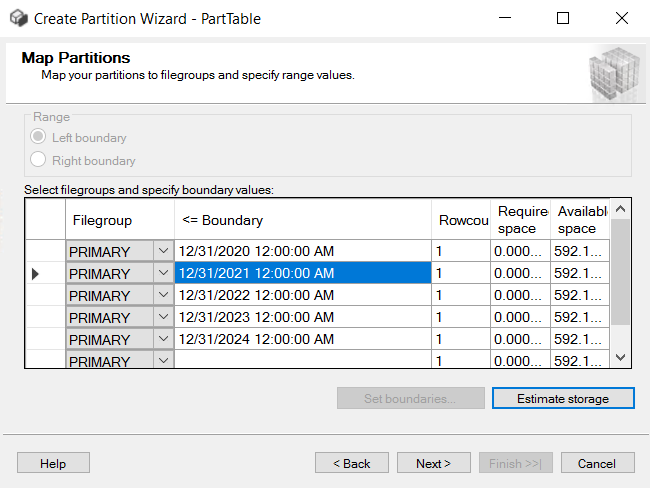
Picture-5:- Mapping the boundaries
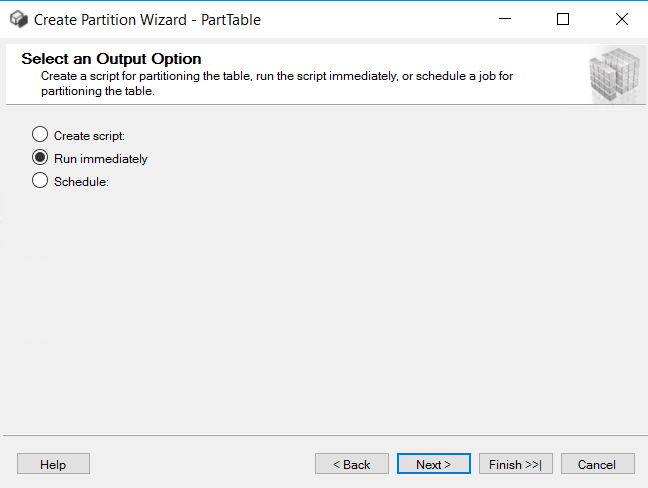
Picture-6:- Select Run immediately option
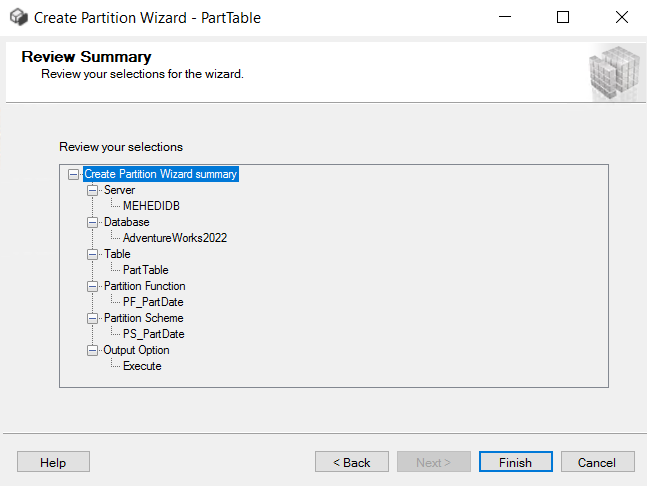
Picture-7:- Review and Finish your actions
Partition Verification
Now, put some data in the table and verify that the partition works fine.
-- Insert data
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2020-01-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2020-02-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2020-12-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2021-01-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2021-01-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2021-02-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2021-12-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2022-01-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2022-02-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2022-12-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2023-01-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2023-02-01 13:30')
INSERT INTO [dbo].[PartTable]([created]) VALUES ('2023-12-01 13:30')
GO
-- Checking whether the table parttioned
SELECT SCHEMA_NAME(t.schema_id) AS SchemaName, *
FROM sys.tables AS t
JOIN sys.indexes AS i
ON t.[object_id] = i.[object_id]
JOIN sys.partition_schemes ps
ON i.data_space_id = ps.data_space_id
WHERE t.name = 'PartTable';
GO
-- Determine the boundary values
SELECT SCHEMA_NAME(t.schema_id) AS SchemaName, t.name AS TableName, i.name AS IndexName,
p.partition_number, p.partition_id, i.data_space_id, f.function_id, f.type_desc,
r.boundary_id, r.value AS BoundaryValue
FROM sys.tables AS t
JOIN sys.indexes AS i
ON t.object_id = i.object_id
JOIN sys.partitions AS p
ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.partition_schemes AS s
ON i.data_space_id = s.data_space_id
JOIN sys.partition_functions AS f
ON s.function_id = f.function_id
LEFT JOIN sys.partition_range_values AS r
ON f.function_id = r.function_id and r.boundary_id = p.partition_number
WHERE
t.name = 'PartTable'
AND i.type <= 1
ORDER BY SchemaName, t.name, i.name, p.partition_number;
GO
-- Check partition wise data
SELECT SCHEMA_NAME(t.schema_id) AS SchemaName, t.name AS TableName, i.name AS IndexName,
p.partition_number AS PartitionNumber, f.name AS PartitionFunctionName, p.rows AS Rows, rv.value AS BoundaryValue,
CASE WHEN ISNULL(rv.value, rv2.value) IS NULL THEN 'N/A'
ELSE
CASE WHEN f.boundary_value_on_right = 0 AND rv2.value IS NULL THEN '>='
WHEN f.boundary_value_on_right = 0 THEN '>'
ELSE '>='
END + ' ' + ISNULL(CONVERT(varchar(64), rv2.value), 'Min Value') + ' ' +
CASE f.boundary_value_on_right WHEN 1 THEN 'and <'
ELSE 'and <=' END
+ ' ' + ISNULL(CONVERT(varchar(64), rv.value), 'Max Value')
END AS TextComparison
FROM sys.tables AS t
JOIN sys.indexes AS i
ON t.object_id = i.object_id
JOIN sys.partitions AS p
ON i.object_id = p.object_id AND i.index_id = p.index_id
JOIN sys.partition_schemes AS s
ON i.data_space_id = s.data_space_id
JOIN sys.partition_functions AS f
ON s.function_id = f.function_id
LEFT JOIN sys.partition_range_values AS r
ON f.function_id = r.function_id and r.boundary_id = p.partition_number
LEFT JOIN sys.partition_range_values AS rv
ON f.function_id = rv.function_id
AND p.partition_number = rv.boundary_id
LEFT JOIN sys.partition_range_values AS rv2
ON f.function_id = rv2.function_id
AND p.partition_number - 1= rv2.boundary_id
WHERE
t.name = 'PartTable'
AND i.type <= 1
ORDER BY t.name, p.partition_number;
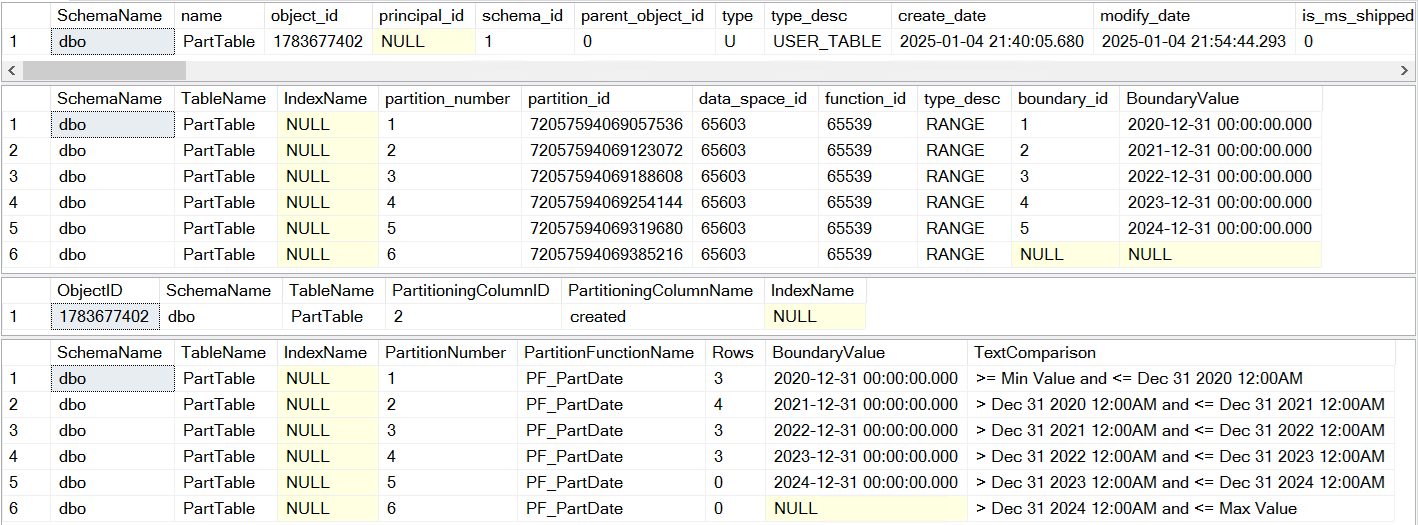
Picture-8:- Partition verification
Important Notes
- Sql Server support 15,000 partitions per table or index. However, using more than 1,000 partitions have negative impacts on memory, partitioned index operations, DBCC commands, and queries.
- Use at least 16 GB of RAM in case you use more partitions
- Ensure tempdb has sufficient memories if you use SORT_IN_TEMPDB index option to perform sorting to build partitioned indexes.
Performance
- Fewer data in every partitions, make the query faster that uses partition elimination. For example, consider your table has 10M data and consider that in scenario - 1, the table is divided into 100 partitions on column X. In scenario - 2, the table is divided into 1,000 partitions on column X. Then
- Query that uses partition elimination on X in where clause and scan, will be faster in scenario - 2, as it has less data to scan. In scenario - 1, it could be slower.
- Query, that use any other column other than X in where clause and scan, will be faster in scenario - 1 as it has less partition to scan.
- Query that uses TOP/MAX/MIN on columns other than the partitioning column may have negative impact on performance as all partitions must be evaluated.
- Query that performs single-row seek or small range scan on columns other than the partitioning column may have negative impact on performance as all partitions must be evaluated.
- In OLTP system partitioning hardly enhances performance if your queries don't include partitioning column in where clause.
Benefits
Partitioning has some operational and performance benefits.
- Accessing part of the table quickly.
- Faster maintenance on one or multiple partitions.
- Performance improvements on frequently used queries.
Caveats
Despite the operational and performance benefits on certain queries, before partitioning make sure that you really need it. As suggested by my favourite Sql Server Consultant Mr. Brent Ozar:
- Partitioning is a major surgery, so, make sure that you have strong logic behind the partitioning.
- Before complaining about slow queries, blocking between readers and writers (inserts or updates) or long-running index maintenance jobs, try to figure out the root cause.
Last words, partitioning is a great tool for performance enhancement and operational excellence. However, make sure that you address all the performance bottleneck before implementing it.